PhD Thesis Defense, Solat Jabeen Sheikh
Title: On Building a Semi-Automated Framework for Constructing Bayesian Networks from Raw Text
PhD Public Defense: Solat Jabeen Sheikh, Lecturer, Department of Computer Science, IBA-SMCS
Advisor: Dr. Sajjad Haider
External Examiners:Dr. Usman Qamar (NUST) | Dr. Agha Ali Raza (LUMS)
Date: February 13, 2026 at 11:00 AM
Venue: 2nd Floor, Conference Room, Tabba Academic Block [North Wing], IBA Karachi, Main Campus
Abstract
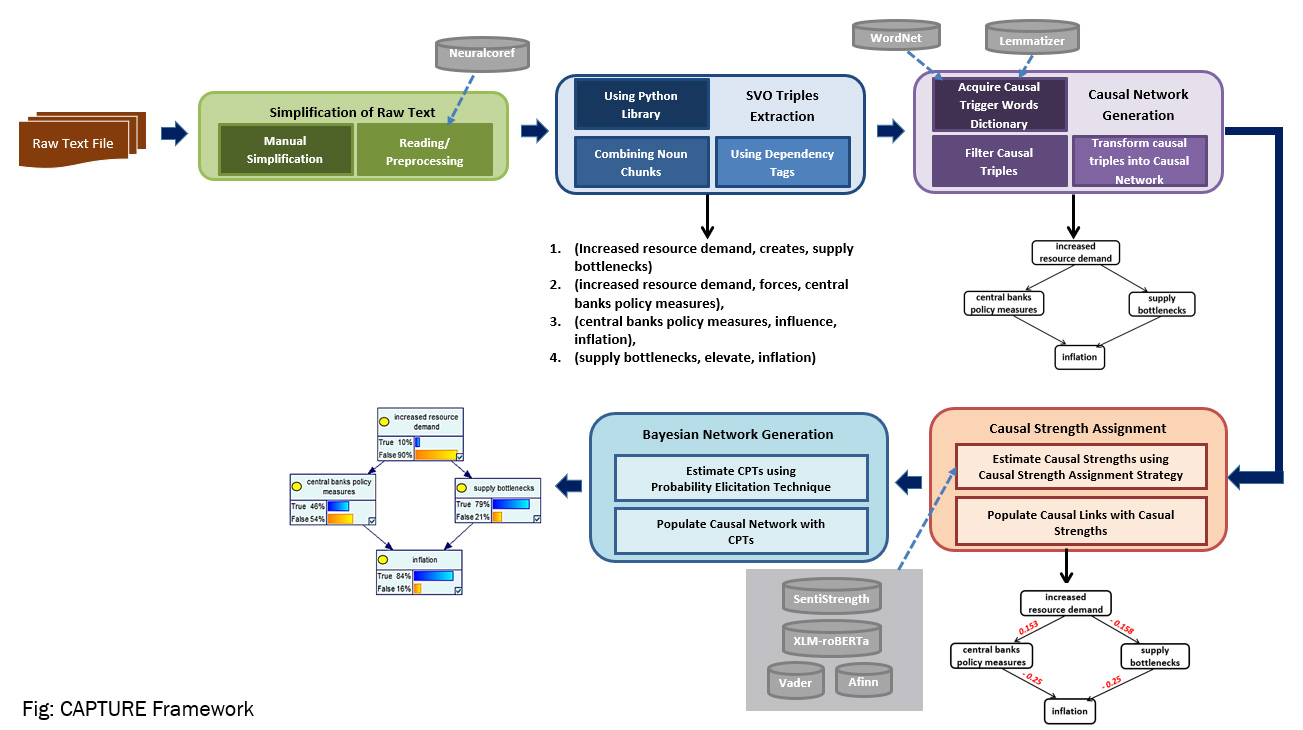
This dissertation addresses the problem of constructing Bayesian Networks (BNs) from raw text. Traditionally, domain experts identify and encode causal relationships based on their knowledge and interpretation of any relevant narrative while constructing a BN. Although effective in capturing expert insight, this method is inherently time-consuming, resource-intensive, and difficult to scale. If quantitative data about relevant variables in a BN is available, then the BN construction process can be automated via structure learning techniques. These techniques infer causal relationships from available datasets. However, the techniques require a substantial amount of data to construct the required probability distributions, rendering them inappropriate for data-scarce domains, where critical information remains embedded in unstructured text. The automated extraction of causality from raw text, on the other hand, presents its own set of challenges due to the linguistic complexity and ambiguity inherent in the texts. Furthermore, many existing systems in this field tend to be domain-specific, thereby lacking generalizability. These challenges imply the need for a generalized and semi-automated human-in-loop approach that is suitable for data-scarce domains. This research, therefore, focuses on developing a generalized and semi-automated framework, named CAPTURE (CAusal and Probabilistic graphical model exTraction from Unstructured Raw tExt), for constructing Bayesian Networks from raw text, with a particular emphasis on data-scarce domains. The devised framework is implemented using two components: SCANER (Semi-automated CAusal Network Extraction from Raw text) and LEAPE (Lexicon and Embedding-based Automated Probability Estimation). In the first phase, SCANER extracts causal networks from the raw text through manual simplification and a set of natural language processing rules. In the second phase, LEAPE transforms these causal networks into Bayesian Networks by automatically estimating and assigning probabilities. This novel approach for estimating probability distributions utilizes lexicon and embedding-based sentiment detection instead of frequency-based methods, thereby making it suitable for data-scarce domains. The performance of CAPTURE is assessed by using raw text from the Political, Water Management (Industrial Control System), Medical, and Food Insecurity domains. F1-score is used to evaluate the causal networks generated in the first phase. For this purpose, the ground truth for the causal links is generated after incorporating feedback from a group of three human evaluators. The BNs generated in the second phase are evaluated using the mean Kullback–Leibler Divergence (KLD). A comparative analysis with a readily available causality extraction system demonstrates the advantages of the presented framework in generating dense and accurate causal networks from the raw text. Furthermore, a comparative analysis with modern-day LLMs, including ChatGPT, Mistral Chat, and Gemini, also highlights the potential advantages of combining them with rule-based methods for improved results. Overall, the results demonstrate the framework’s effectiveness in accurately eliciting foundational CPTs across diverse datasets.
Learn More: https://www.sciencedirect.com/science/article/pii/S0952197623003731