On Building an Interpretable Clustering Approach For Urdu Language
PhD Defense Talk
On Building an Interpretable Clustering Approach For Urdu Language
by Zarmeen Nasim
Advisor: Dr. Sajjad Haider
External Examiners: Dr. Agha Ali Raza (LUMS), and Dr. Muhammad Hanif (GIKI)
Venue: Conference Room, Tabba Academic Block, Main Campus, IBA Karachi
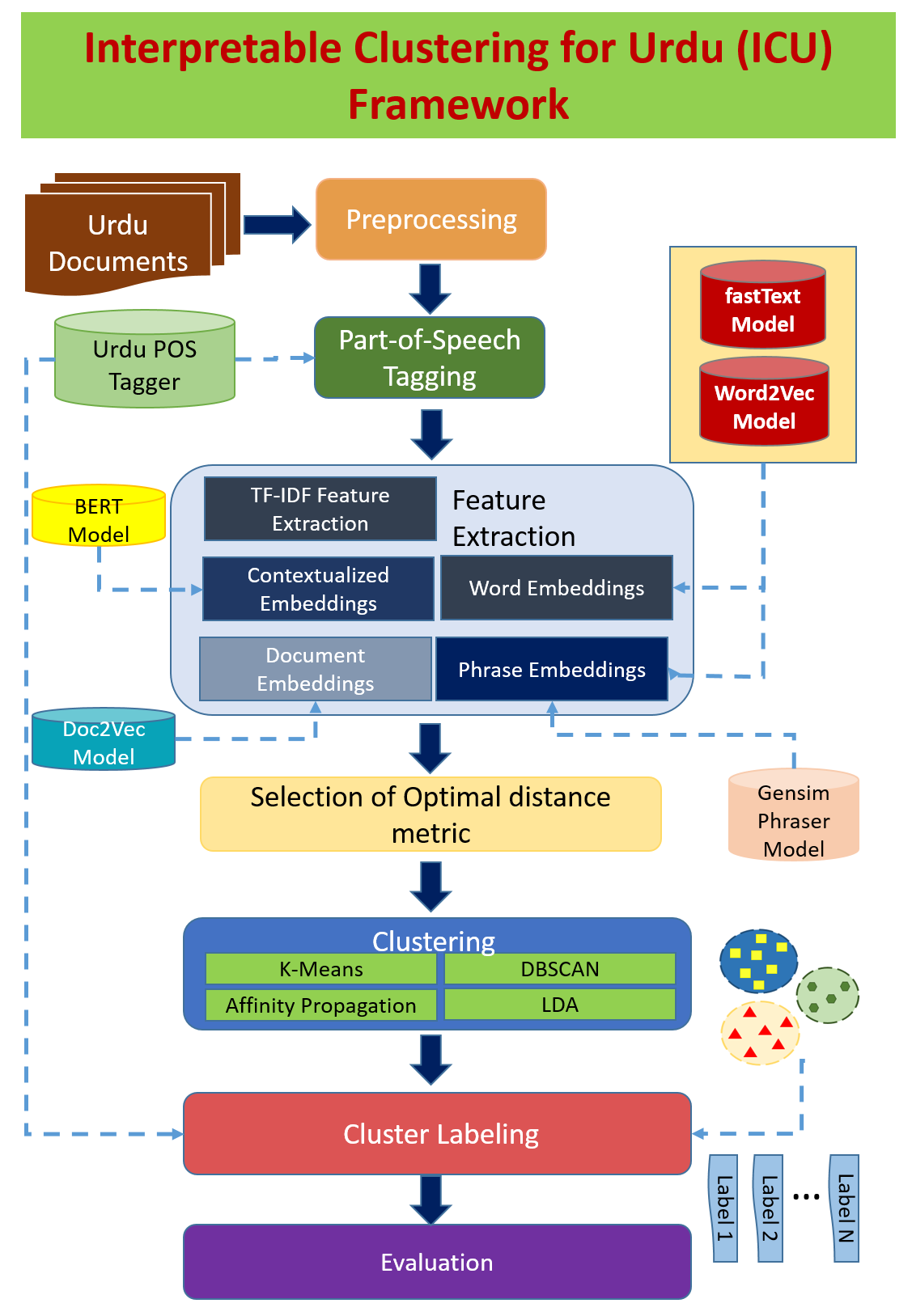
Abstract:
This dissertation addresses the problem of producing interpretable cluster topic labels for a given set of documents in Urdu, a low resource language. Document clustering and topic modeling methods help in determining groups of semantically similar documents. However, the existing clustering and topic modeling techniques produce a collection of words, often uninterpretable, as suggested topics without integrating them into a semantically correct phrase. This research presents an Interpretable Clustering for Urdu (ICU) framework that not only clusters similar documents but also assigns meaningful labels to the resultant clusters. The development of the framework required an accurate Part of Speech (POS) tagger for the Urdu Language. The required tagger is modeled using a publicly available corpus of many million sentences. Using state-of-the-art semantically rich feature extraction approaches including Word2Vec and BERT, the framework, in the next step, places a given set of documents into different clusters. Finally, the framework applies a novel algorithm to produce syntactically correct phrases representing interpretable topics.
In the first phase, the framework evaluates various distance measures on the clustering task. It then applies three clustering algorithms: K-Means, Affinity Propagation, and Density-based spatial clustering of applications with noise (DBSCAN) using the optimal distance function to produce clusters for a given set of documents. The Latent Dirichlet Allocation topic model was also assessed for comparison with clustering algorithms. The evaluation was performed on the Urdu News Headlines and Urdu Tweets datasets using extrinsic measures. In addition, several word embedding models are trained on Urdu News and Twitter using techniques such as Word2Vec, Doc2Vec, and fastText.
In the next step, the framework performs automatic cluster labeling. This research presents an unsupervised method for cluster labeling based on the noun phrase chunking. The proposed method is compared with the four other statistical-based methods, including Z-Order, M-Order, T-Order, and YAKE. In addition to the statistical measures-based labeling schemes, the approach is also compared with the two graph-based techniques: Text Rank and Position Rank. The experiments were performed on the datasets of Urdu News headlines and Urdu Tweets. The proposed approach's effectiveness was evaluated using cosine similarity, Jaccard Index, and the feedback received from human evaluators. The results showed that the proposed method outperformed other methods. It was found that the labels produced were more relevant and semantically rich in contrast to other approaches.
Currently, the framework does not assess the semantic relatedness among the noun chunks while doing cluster labeling. This requires an extensive knowledge source that documents the relationship among words. In the future, we plan to improve the cluster labeling algorithm by utilizing sophisticated natural language generation (NLG) techniques.